Add files to Cloud Storage via URL
Categories:
Prior reading: Data resources overview
Purpose: This document provides instructions for adding files to Google Cloud Storage buckets via URL.
Introduction
Verily Workbench allows users to add files to Google Cloud Storage buckets by providing a URL to some data that can be written to a file. Any public URL can be provided so long as it's resolvable. Additionally, Verily Workbench will perform special parsing logic for certain URL patterns. Below is a guide on how to use this feature, as well as an explanation of special rules that apply to specific URL RegEx patterns.
Adding files via URL
To begin the process of adding a file to a Google Cloud Storage bucket from a given URL, first select an existing bucket in the Resources tab of a workspace. Then click the Add file via URL button in the details pane. This button is also available when clicking folders within the bucket browser.
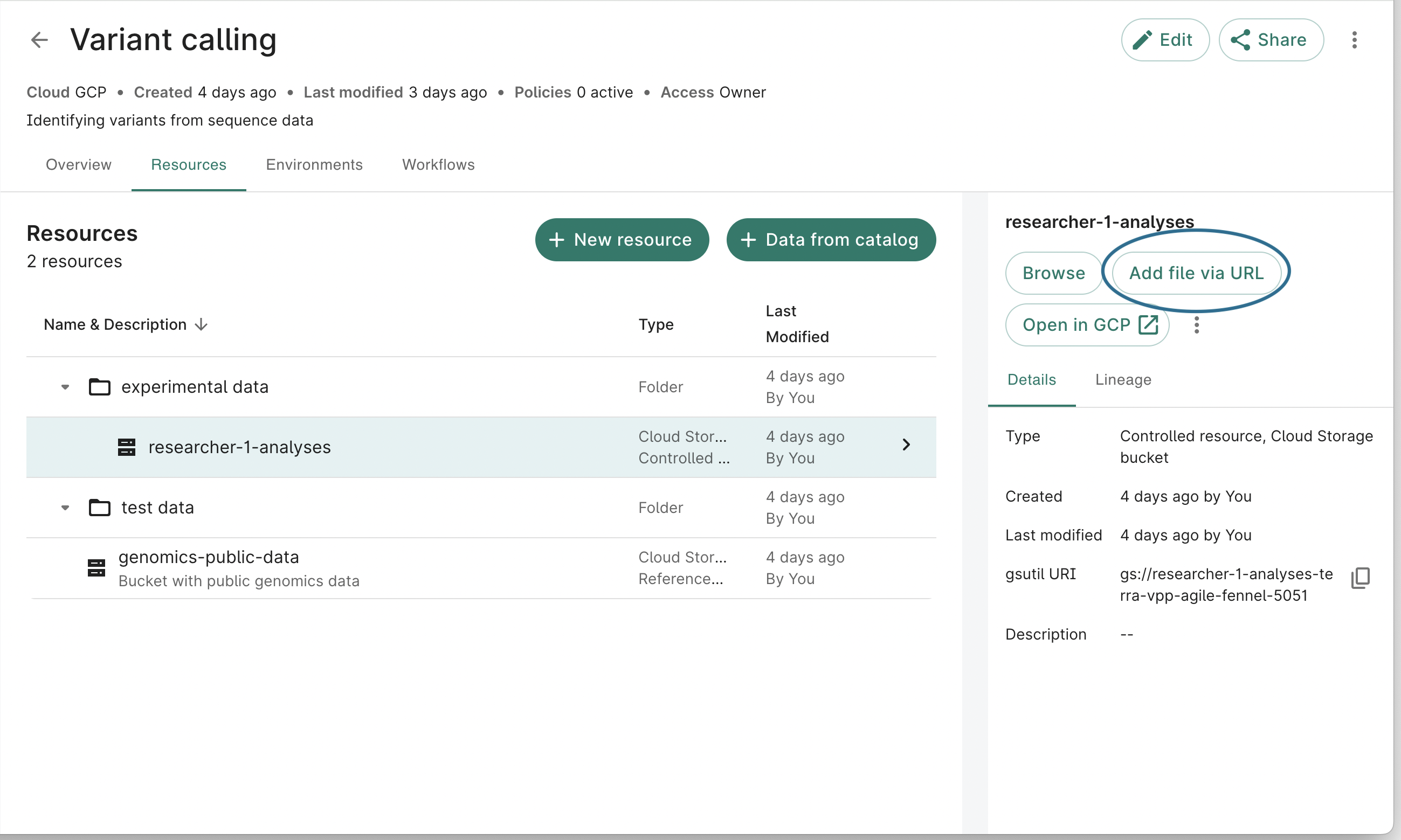
A dialog will open where you can add the source URL and the destination file path in the bucket. In this example, we will use the Cram To Bam WDL workflow stored here. You can edit the default file name and prefix it with a folder path in order to specify a destination folder (the folder does not need to exist).
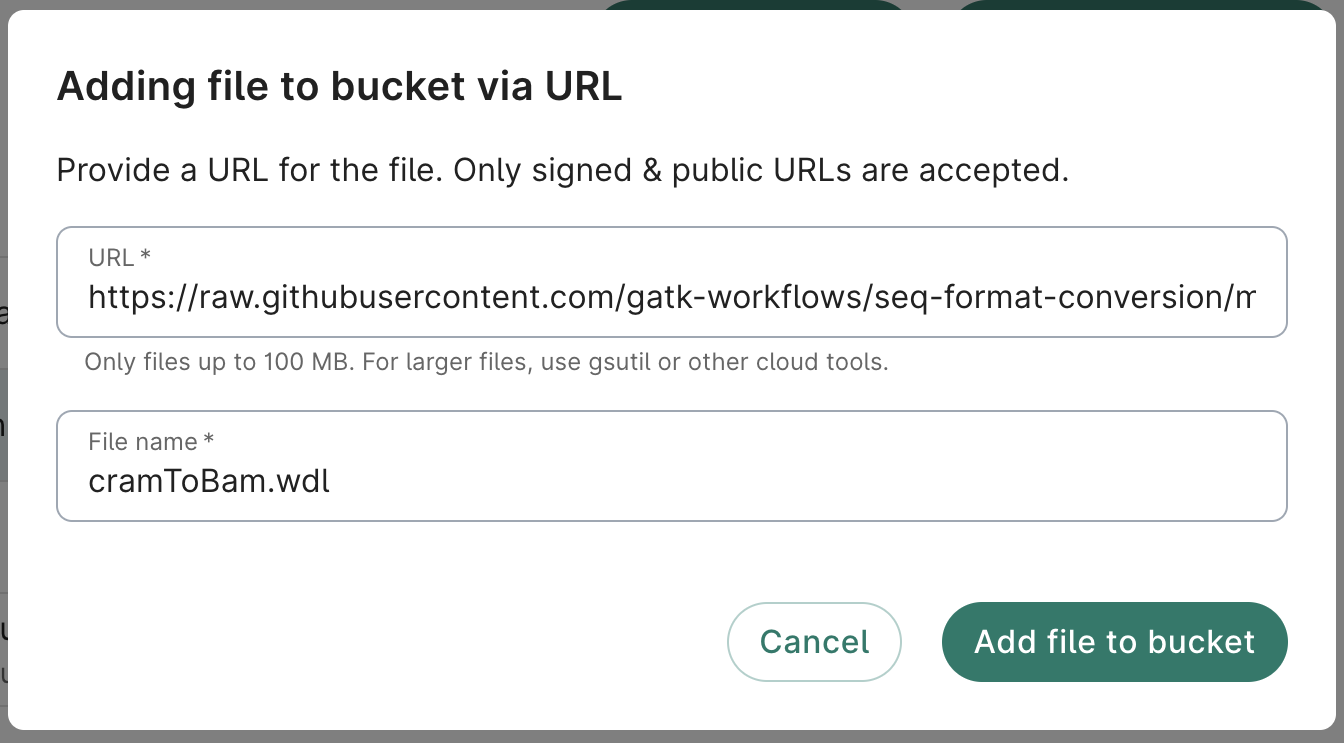
After clicking the Add file to bucket button, you'll be presented with a success dialog.
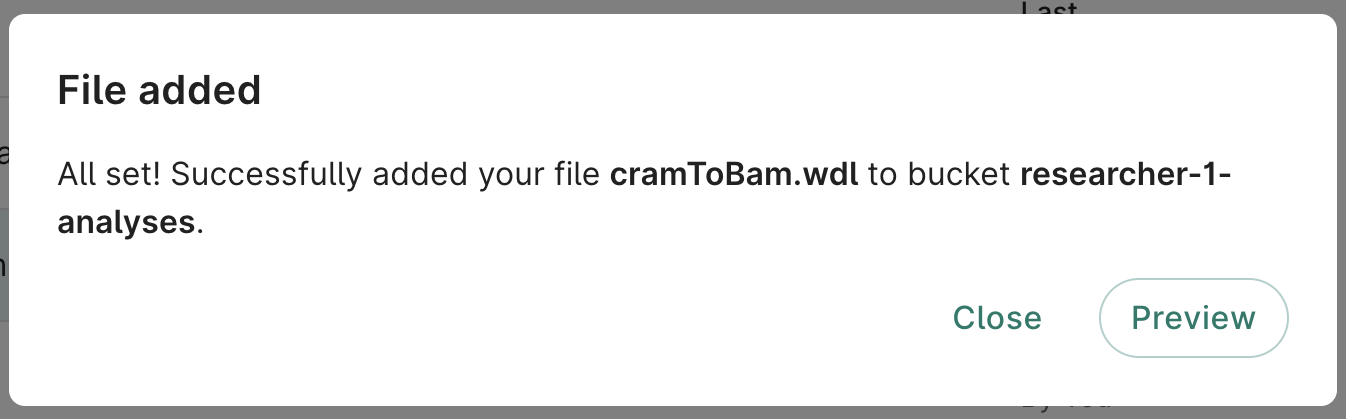
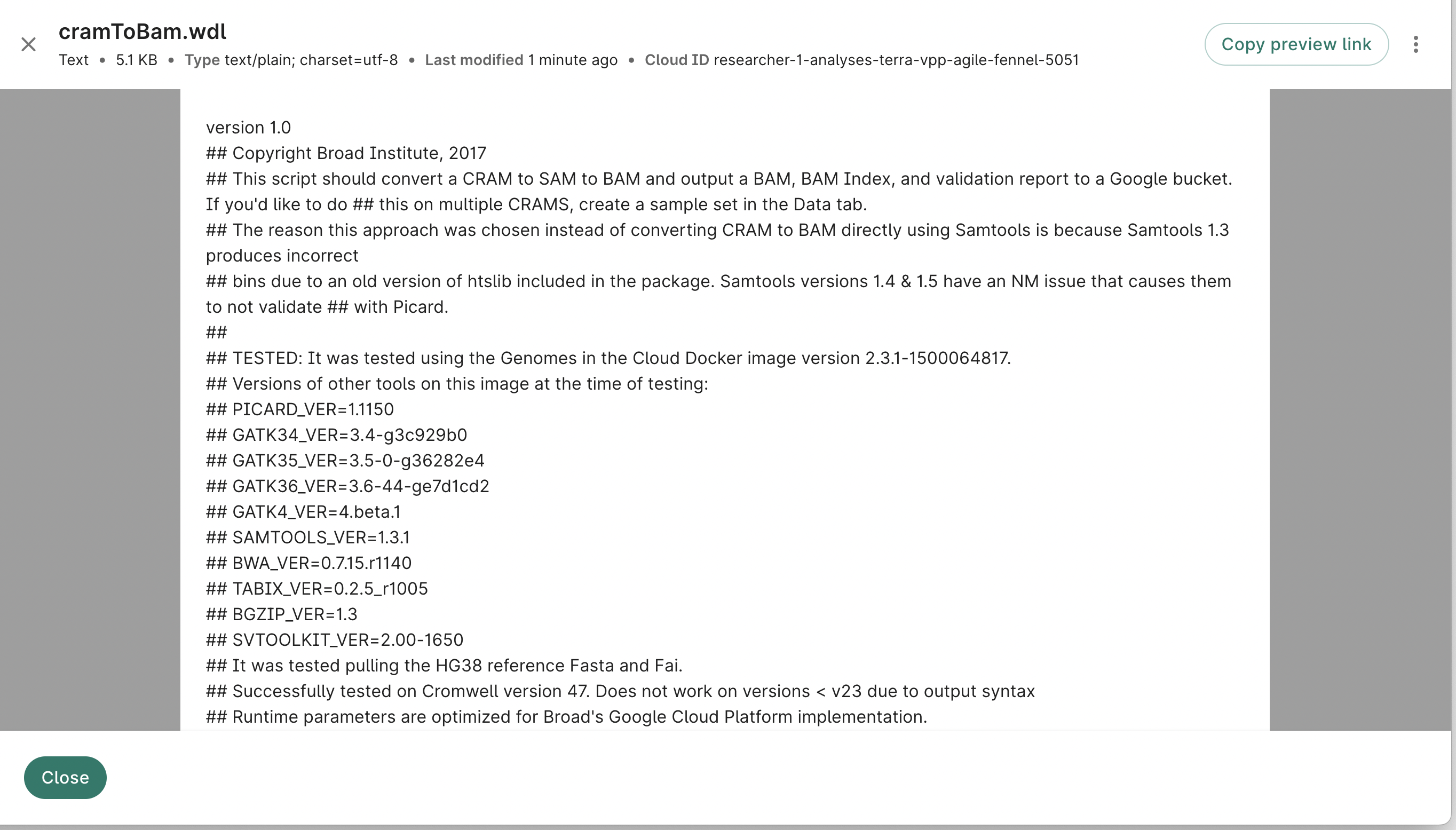
From here, you can click the Preview button in order to see the file in the bucket.
Custom logic for specific URL patterns
As previously mentioned, Verily Workbench uses custom logic when parsing URLs that match a specific pattern.
GA4GH Data Connect URLs
Data Connect is a standard for discovery and search of biomedical data, developed by the Discovery Work Stream of the Global Alliance for Genomics & Health. Verily Workbench provides support for importing data from the table/data and table/search endpoints of the specification.
If a given source URL matches the RegEx pattern /table/([^/]+)/(data|search)$, the Add File via URL flow will attempt to parse the resulting data with the following logic:
- The system will verify that the resulting data matches the JSON specification of the Data Connect standard. If it doesn't, it will attempt to import the data with no custom parsing.
- The system will make pagination requests as necessary.
- The system will parse the full JSON representation of the table data into CSV format.
- The system will write the CSV file to Google Cloud Storage.
In the end, the researcher will have access to a CSV representation of the table data they are interested in.
Limitations
The system is currently only built to support data up to a size of 100 MB. Our hope is that users will find this experience useful in transferring small amounts of data, and rely instead on standard tools such as gsutil when transferring large files. Additionally, the system currently performs the data transfer synchronously, meaning users will need to wait while the transfer completes. As such, using this tool only for smaller files is recommended.
Last Modified: 8 November 2024